


Imagine you are a chef trying out recipes for the best chocolate cake. Each time you tweak an ingredient – a bit more flour here, a little less sugar there – you are essentially conducting an experiment. Now, picture doing this a hundred times with slight variations each time. Remembering every single tweak and how it affected the cake's taste and texture would be a daunting task. This is similar to what data scientists face when they build and improve machine learning models; they tweak and adjust, just like you would with your cake recipe.

Imagine perfecting your chocolate cake recipe, where each ingredient tweak is a magical touch. Now, wouldn't it be nice if you had a friend standing by, jotting down every little change and its magical effect in an automatic journal? MLflow is like that trusted journal-keeping friend. It notes every change ('parameters') and its effect ('performance metrics') as you bake. It's your secret ingredient tracker, ensuring you can recreate your success i.e. reproduce results with ease. In the busy kitchen of machine learning, MLflow is your sous-chef, capturing every insight so you can recreate success anytime.
Step by step code walk through
import mlflow
import mlflow.sklearn
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_scoreThis section of the code brings in all the essential libraries we need. Key among them, highlighted in the first two lines, are the imports for MLflow. This tool is crucial for tracking our experiments, managing models, and streamlining the machine learning workflow. The other imports include pandas for data handling, Scikit-Learn for machine learning algorithms, and functions for model training and evaluation.
folder_path = "/dbfs/mnt/archive/blog/"
df = pd.read_csv(folder_path+'breast_cancer.csv')For our project, we're using DBFS on the Databricks platform for streamlined data management, particularly with 'mnt' as a quick-access point to external storage. Our code accesses 'breast_cancer.csv' from the path "/dbfs/mnt/archive/blog/" in our Azure data lake, loading it into a DataFrame, df, for efficient data handling and analysis. The dataset used is the Breast Cancer dataset (the link to the dataset is provided in the reference section below).
X = df.drop(df.columns[1], axis=1)
y = df.iloc[:,1]This part of the code involves separating the features (X) and the target label (y). For this, we remove the second column, which represents our labels (Malignant and Benign types of cancer, denoted as 'M' and 'B'), from the dataset to form X. The 'y' variable is then assigned these label values.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)We now use the train_test_split function to divide our data into training and testing sets, with 80% used for training and 20% reserved for testing.
experiment_name = "/Users/user_name/name_of_experiment"
if not mlflow.get_experiment_by_name(experiment_name):
mlflow.create_experiment(experiment_name)This code snippet efficiently initiates an experiment in MLflow. It begins by specifying a unique name for the experiment. If the experiment does not already exist in MLflow's records, it is created.
mlflow.set_experiment(experiment_name)This selects the specific experiment in MLflow, our project's tracking tool, ensuring all our model's activities and results are neatly recorded and organized under this name for easy tracking and comparison.
n_estimators_options = [50, 100, 150]
max_depth_options = [2, 4, 6]In our project, we're fine-tuning our RandomForestClassifier model by testing different hyperparameters: n_estimators_options = [50, 100, 150] for the number of trees, and max_depth_options = [2, 4, 6] for the maximum tree depth. This approach helps us identify the best settings for optimal model performance.
for n_estimators in n_estimators_options:
for max_depth in max_depth_options:
with mlflow.start_run():
# Create and train the model
rf = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth, random_state=42)
rf.fit(X_train, y_train)
# Make predictions and calculate accuracy
predictions = rf.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
# Log parameters, metrics, and the model
mlflow.log_param("n_estimators", n_estimators)
mlflow.log_param("max_depth", max_depth)
mlflow.log_metric("accuracy", accuracy)
mlflow.sklearn.log_model(rf, "model")
print(f"Model with n_estimators={n_estimators}, max_depth={max_depth} has accuracy: {accuracy}")This code snippet is like a search for the best settings for our RandomForestClassifier model. We're trying out different combinations of n_estimators (the number of trees) and max_depth (maximum tree depth).
For each combination, we:
Create a model with those settings.
Train the model using our training data.
Make predictions and measure its accuracy.
Record these settings and accuracy in our tracking system, MLflow.
Print the accuracy to see how well the model performed.
This process helps us discover the ideal configuration that gives us the highest accuracy for predicting cancer types.
When we head over to the "Machine Learning" section and click on "Experiments," we'll discover our MLflow experiment, named as we specified earlier. Inside, we'll find a collection of runs, each with its unique combination of hyperparameters (max_depth and n_estimators).
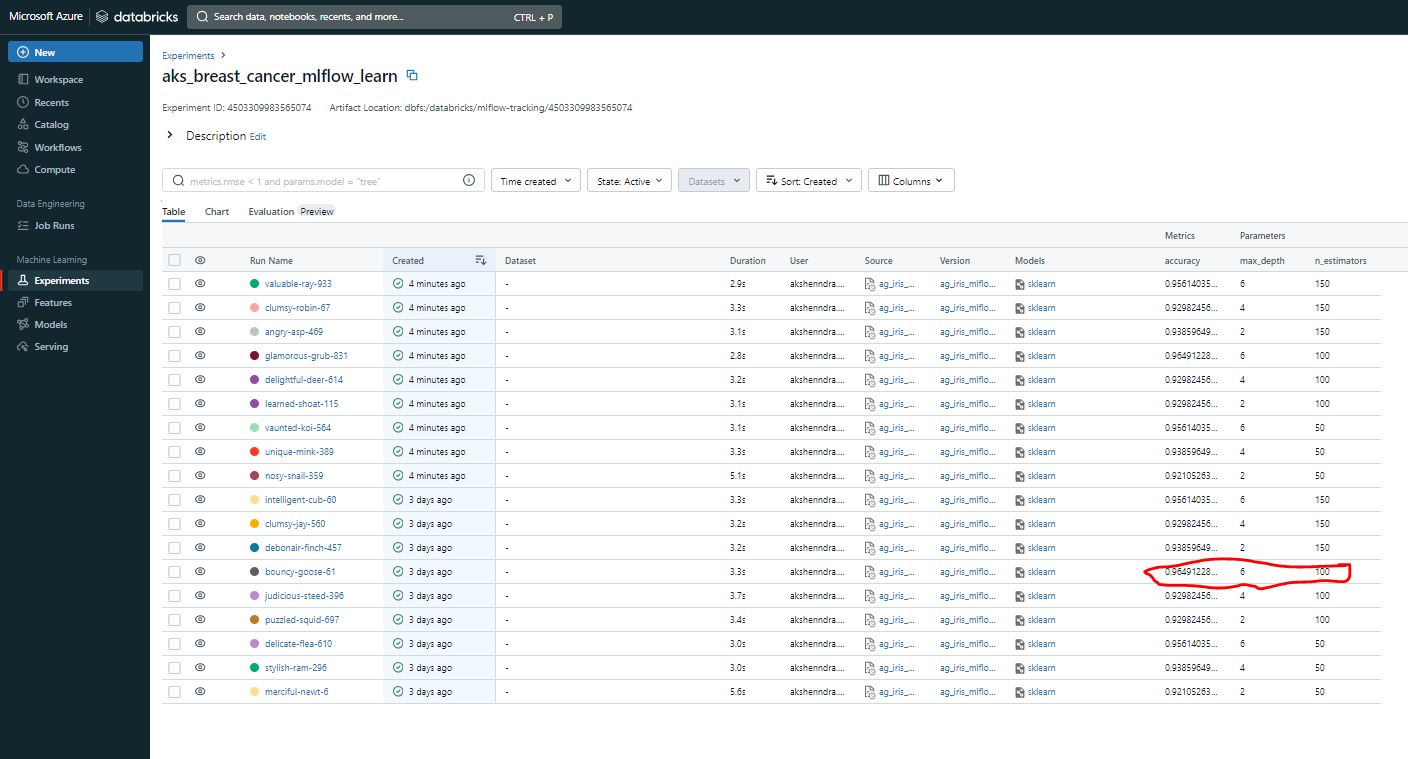
For each run, we've gathered crucial information:
The time it took to complete.
Details about the model and its version.
Most importantly, the automatically recorded accuracy.
Take a look at the highlighted section in red. It's where we have achieved our highest accuracy, a remarkable 0.96. This outstanding result was achieved when we set max_depth to 6 and n_estimators to 100. This underscores the crucial role of MLflow in our journey. It vividly demonstrates how MLflow's ability to record and track hyperparameter tuning can lead to significant improvements in our model's accuracy when solving generalized machine learning optimization problems.
Conclusion
In a nutshell, MLflow is our reliable companion in the field of machine learning. It streamlines experiments, manages models, and enhances overall performance, among other capabilities. MLflow simplifies the journey and elevates outcomes in the world of data science and machine learning.
References
Dataset: For this project, we used the Breast Cancer Wisconsin dataset, which is publicly available on Kaggle. The code is available here .
 | A guest post by
|